Overview
Our Personal Chatbot delivers immediate, context-aware responses through an AI model connected with a custom document knowledge base.
It takes policy documents (leave policy, working hours policy, professional wear) of a company as a demo dataset and generates vector embeddings to store them on Pinecone for semantic search.
The chatbot is based on an n8n workflow and can answer user questions via conversation. This makes sure that responses are not too general; instead it’s customized to your particular dataset, making it perfect for support bots, internal knowledge assistance, or domain specific Q&A systems.
Objective
The main objective is to furnish instant, personalized, and accessible data from the policy document, letting the users to swiftly find the answer they are looking for and comprehend complex policy.
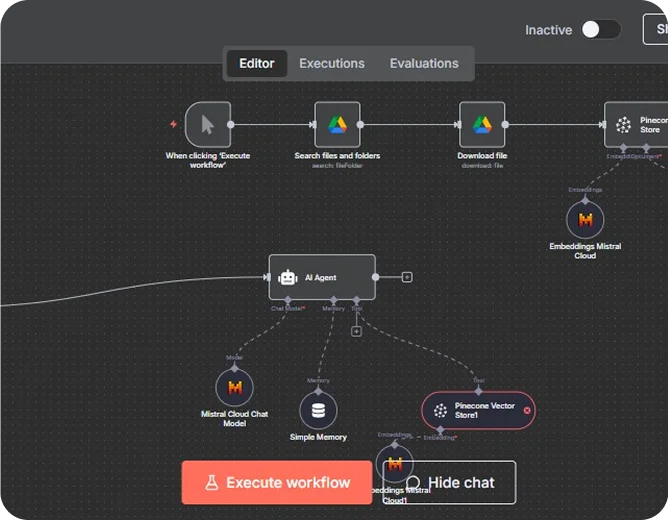
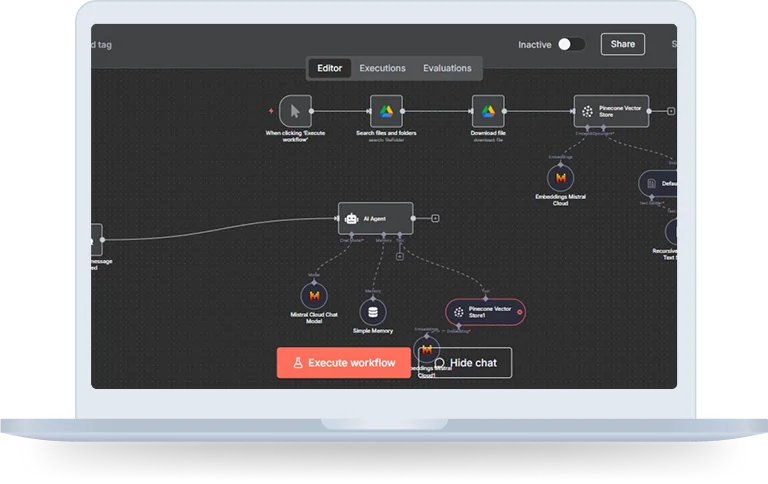
How does it work?
Step 1: Chat Trigger Node
- Upon receiving a message, the chat trigger node immediately activates the workflow.
- It enables the creation of chatbots and conversational AI Agents by providing a mechanism to receive user queries and initiate the processing of that query in the workflow.
Step 2: AI Agent Node Setup
- A chatbot query is received by the AI Agent node, it connects the chatbot query along with the vector store and AI model for retrieving the relevant information related to the query.
- The Mistral Cloud Model processes the input, generates a response, and sends it back to the AI Agent node.
Step 3: Document Search and Retrieval
- Execute Workflow Trigger: To initiate the process when you want to manually run the bot set-up.
- Search Files and Folders: Find policy documents from the file store you select.
- Download File: Downloads the entire contents of those documents.
Step 4: Data Processing & Vector Storage
- Default Data Loader: Retrieves the document text to n8n for further processing.
- Recursive Character Based Text Splitter: Splits up large texts into small, meaningful pieces for more effectiveness.
- Embeddings (Mistral Cloud): Converts text chunks to vector embeddings, this process involves translating the textual data into numerical form.
- Pinecone Vector Store: fetch these embeddings and allows fast semantic search and retrieval of the results.
Step 5: Memory & Context Handling
The Simple Memory Node tracks previous conversation exchanges, to keep context for chatbot when interacting with several queries.
Step 6: Response Generation
- The AI Agent searches Pinecone to identify the most relevant document chunks.
- The Mistral Cloud Model leverages these chunks as context to provide the correct, contextual answers for the chatbot.
Technology Stack Included
Key Benefits
Domain Related Answers
The bot only answers based on what your document contains so you can have less errors and reliable, situated pieces of information.
Quick Finding of Information
Semantic search instantly retrieves the most relevant content. So there is no need for searching.
Knowledge Base Integration
Allows it to fit any type of content such as policies, manuals and training resources.
Continuous Learning
The vector store can be easily updated to reflect changes in documents without having to re-index the database.
Scalable
It scales for personal or organizational knowledge management.
Closure
In conclusion, Personal Chatbot delivers immediate, context-aware responses through an AI model connected with a custom document knowledge base. It takes policy documents of a company as a demo dataset and generates vector embeddings to store them on Pinecone for semantic search.